






解锁最大推理能力:深入研究80GB A100 GPU 上的Llama2–70B
在不断发展的自然语言处理领域,模型的性能是最重要的问题。研究人员、工程师和数据科学家不断利用日益强大的硬件和复杂的算法突破可能的界限。其中一项追求是确定 Llama2-70B 等模型在专用硬件(如 80GB A100 GPU)上运行时的最大推理能力。在本文中,我们深入探讨了此类调查的理论、实践和结果。
为什么要研究推理能力?
出于多种原因,了解模型的最大推理能力至关重要。首先,它可以帮助研究人员和开发人员就模型部署做出明智的决策。了解模型在特定硬件上的限制对于高效资源分配和避免意外瓶颈至关重要。
其次,这些知识对于在实时应用程序中依赖自然语言处理模型的组织至关重要。聊天机器人、虚拟助理和自动化客户支持系统等应用程序需要模型能够快速、准确地做出响应。确定推理能力可确保这些应用程序能够有效地处理不同的工作负载。
Llama2–70B 型号
在本次研究中,Llama2-70B 模型占据了中心位置。Llama2–70B 是 Llama2 模型的变体,具有 4 位量化功能。术语“4 位量化”是指一种用于降低模型权重精度的技术,使模型的存储和计算效率更高,同时牺牲最小的精度。
理论与实践
为了测试 Llama2-70B 模型在 80GB A100 GPU 上的最大推理能力,我们要求一位研究人员部署 Llama2 模型并将其推向极限,以查看它到底可以处理多少个令牌。不同的输入标记长度对应于不同的近似字数。每次测试运行时都会监控并记录 GPU 使用情况。
我们还将其与理论计算进行了比较,看看它们在现实世界中的表现如何。
为了计算 Llama2 推理所需的内存,我们需要考虑以下两点:
1.模型权重所需的内存。
2. 推理过程中中间变量所需的内存。
模型权重所需的内存
在计算部署模型所需的 GPU 使用率时,我们主要考虑的是模型的参数大小。Llama2–70B 模型是一个拥有 700 亿个参数的大型语言模型。当我们使用 4 位量化时,这意味着每个参数将使用 4 位来存储。因此,对于 700 亿个参数,我们需要等于 70 * 1000000000 * 4 位的 GPU 内存。这大约相当于 35 GB。
中间变量所需的内存
在计算模型中推理所需的中间变量时,最重要的中间变量包括注意力机制中的Query、Key和Value矩阵,以及Query矩阵与Key矩阵相乘得到的Attention Weights矩阵。下表显示了这四个矩阵的形状及其在 Llama2-70b 模型中的实际大小。

由于本实验中输入的token长度超过2000,因此四个矩阵中内存密集的部分是注意力权重矩阵。在调试 HuggingFace 的代码来推断 Llama2-70b 模型时,观察到通过将 Query 矩阵与 Key 矩阵相乘来计算 Attention Weights 矩阵时,其 dtype 为 16 位,但在实际计算过程中使用了两次空间。此外,在 Softmax 计算期间,dtype 扩展到 32 位。因此,可以理解,模型实际推理时,需要四倍的16位Attention Weights矩阵。
因此,我们可以使用以下公式来估计中间变量所需的内存:
内存(以 GB 为单位):
= 4 * 16位注意力权重矩阵 / 8 / 1000 / 1000 / 1000
= 4 * 16 * 注意力权重矩阵的大小 / 8 / 1000 / 1000 / 1000
= 4 * 16 * (1 * 64 * 输入长度 * 输入长度) / 8 / 1000 / 1000 / 1000
= (4 * 16 * 64 / 8 / 1000 / 1000 / 1000) * 输入长度 * 输入长度
= 5.12 * 10e-7 * 输入长度**2
用于推理的总内存使用量
根据上面提到的模型权重和中间变量两部分,我们可以估计 GPU 的总使用量(以 GB 为单位):
总内存使用量 = 模型权重内存使用量 + 中间变量内存使用量
≈ 35 + 5.12 * 10e-7 * 输入长度**2
结果和启示
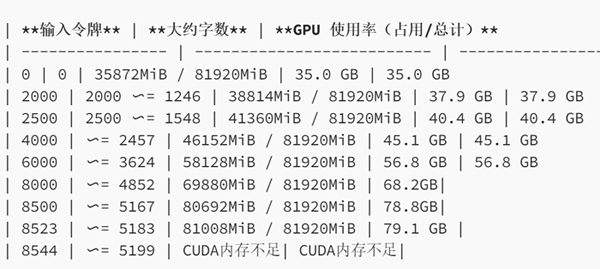
我们随后进行了实验来评估真实场景中 GPU 的使用情况。在我们的实验中,我们使用 HuggingFace 框架对 4 位量化的 Llama2-70b 模型进行推理。下表展示了不同负载下的GPU使用情况:
然后,我们将实际实验数据点(蓝色)与我们计算的理论使用曲线(红色)绘制在一张图表上,如下所示:
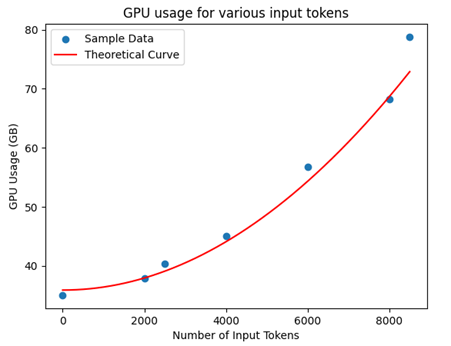
上图的结果可以清楚地了解 Llama2–70B 模型在 80GB A100 GPU 上的行为:
· 当不提供输入标记时,GPU 使用量约为 35.0 GB,这与我们计算的模型参数值相符。
· 我们可以看到我们测试的实际GPU使用率与我们计算的理论曲线非常吻合。随着输入令牌计数的增加,GPU 使用率呈二次方上升。这与我们理论计算公式中输入长度的二次项一致。
· 根据 GPU 的容量限制,最大推理能力达到约 8500 个令牌。
8500 个令牌的推理能力大致相当于 5100 个单词,代表 GPU 得到充分利用的时刻,输入令牌长度的进一步增加会导致 CUDA 内存不足错误。此外,该观察结果与理论理解相一致,即 Transformers 中的注意力机制是 Llama2-70B 等模型的关键组成部分,随着输入长度的增加,GPU 使用率会呈二次方增长。
基础 Llama2–70B 模型的上下文长度为 4096 个标记,因此该实验表明该模型可以轻松安装到一张 80Gb 卡上(使用 4 位量化)。然而,由于存在扩展可用上下文窗口的技术,因此了解一张卡可以处理的最大值极其重要,即使它超出了理论最大值。
结论
为了最大化自然语言处理模型的推理能力,理解模型架构和硬件之间的相互作用至关重要。在这项研究中,4 位量化的 Llama2-70B 模型在 80GB A100 GPU 上展示了大约 8500 个令牌的最大推理能力。
这一发现为旨在优化自然语言处理管道并确保在专用硬件上高效部署模型的从业者和组织提供了宝贵的见解。它还强调了仔细平衡模型复杂性和硬件资源以在实际应用中实现最佳性能的重要性。
信息来源:https://nigelcannings.medium.com/unlocking-maximum-inference-capability-a-deep-dive-into-llama2-70b-on-an-80gb-a100-gpu-2ab1158d6b0b
2023年人工智能训练与推理工作站、服务器、集群硬件配置推荐
https://xasun.com/article/110/2508.html


